Standard procedure¶
Here is a standard procedure based on pyXpcm. This will show you how to create a model, how to fit/train it, how to classify data and to visualise results.
Create a model¶
Let’s import the Profile Classification Model (PCM) constructor:
[2]:
from pyxpcm.models import pcm
A PCM can be created independently of any dataset using the class constructor.
To be created a PCM requires a number of classes (or clusters) and a dictionary to define the list of features and their vertical axis:
[3]:
z = np.arange(0.,-1000,-10.)
pcm_features = {'temperature': z, 'salinity':z}
We can now instantiate a PCM, say with 8 classes:
[4]:
m = pcm(K=8, features=pcm_features)
m
[4]:
<pcm 'gmm' (K: 8, F: 2)>
Number of class: 8
Number of feature: 2
Feature names: odict_keys(['temperature', 'salinity'])
Fitted: False
Feature: 'temperature'
Interpoler: <class 'pyxpcm.utils.Vertical_Interpolator'>
Scaler: 'normal', <class 'sklearn.preprocessing._data.StandardScaler'>
Reducer: True, <class 'sklearn.decomposition._pca.PCA'>
Feature: 'salinity'
Interpoler: <class 'pyxpcm.utils.Vertical_Interpolator'>
Scaler: 'normal', <class 'sklearn.preprocessing._data.StandardScaler'>
Reducer: True, <class 'sklearn.decomposition._pca.PCA'>
Classifier: 'gmm', <class 'sklearn.mixture._gaussian_mixture.GaussianMixture'>
Here we created a PCM with 8 classes (K=8) and 2 features (F=2) that are temperature and salinity profiles defined between the surface and 1000m depth.
We furthermore note the list of transform methods that will be used to preprocess each of the features (see the preprocessing documentation page for more details).
Note that the number of classes and features are PCM properties accessible at pyxpcm.pcm.K and pyxpcm.pcm.F.
Load training data¶
pyXpcm is able to work with both gridded datasets (eg: model outputs with longitude,latitude,time dimensions) and collection of profiles (eg: Argo, XBT, CTD section profiles).
In this example, let’s import a sample of North Atlantic Argo data that come with pyxpcm.pcm:
[5]:
import pyxpcm
ds = pyxpcm.tutorial.open_dataset('argo').load()
print(ds)
<xarray.Dataset>
Dimensions: (DEPTH: 282, N_PROF: 7560)
Coordinates:
* DEPTH (DEPTH) float32 0.0 -5.0 -10.0 -15.0 ... -1395.0 -1400.0 -1405.0
Dimensions without coordinates: N_PROF
Data variables:
LATITUDE (N_PROF) float32 ...
LONGITUDE (N_PROF) float32 ...
TIME (N_PROF) datetime64[ns] ...
DBINDEX (N_PROF) float64 ...
TEMP (N_PROF, DEPTH) float32 ...
PSAL (N_PROF, DEPTH) float32 ...
SIG0 (N_PROF, DEPTH) float32 ...
BRV2 (N_PROF, DEPTH) float32 ...
Attributes:
Sample test prepared by: G. Maze
Institution: Ifremer/LOPS
Data source DOI: 10.17882/42182
Fit the model on data¶
Fitting can be done on any dataset coherent with the PCM definition, in a sense that it must have the feature variables of the PCM.
To tell the PCM model how to identify features in any xarray.Dataset, we need to provide a dictionary of variable names mapping:
[6]:
features_in_ds = {'temperature': 'TEMP', 'salinity': 'PSAL'}
which means that the PCM feature temperature is to be found in the dataset variables TEMP.
We also need to specify what is the vertical dimension of the dataset variables:
[7]:
features_zdim='DEPTH'
Now we’re ready to fit the model on the this dataset:
[8]:
m.fit(ds, features=features_in_ds, dim=features_zdim)
m
[8]:
<pcm 'gmm' (K: 8, F: 2)>
Number of class: 8
Number of feature: 2
Feature names: odict_keys(['temperature', 'salinity'])
Fitted: True
Feature: 'temperature'
Interpoler: <class 'pyxpcm.utils.Vertical_Interpolator'>
Scaler: 'normal', <class 'sklearn.preprocessing._data.StandardScaler'>
Reducer: True, <class 'sklearn.decomposition._pca.PCA'>
Feature: 'salinity'
Interpoler: <class 'pyxpcm.utils.Vertical_Interpolator'>
Scaler: 'normal', <class 'sklearn.preprocessing._data.StandardScaler'>
Reducer: True, <class 'sklearn.decomposition._pca.PCA'>
Classifier: 'gmm', <class 'sklearn.mixture._gaussian_mixture.GaussianMixture'>
log likelihood of the training set: 38.825127
Note
pyXpcm can also identify PCM features and axis within a xarray.DataSet with variable attributes. From the example above we can set:
ds['TEMP'].attrs['feature_name'] = 'temperature'
ds['PSAL'].attrs['feature_name'] = 'salinity'
ds['DEPTH'].attrs['axis'] = 'Z'
And then simply call the fit method without arguments:
m.fit(ds)
Note that if data follows the CF the vertical dimension axis attribute should already be set to Z.
Classify data¶
Now that the PCM is fitted, we can predict the classification results like:
[9]:
m.predict(ds, features=features_in_ds, inplace=True)
ds
[9]:
<xarray.Dataset>
Dimensions: (DEPTH: 282, N_PROF: 7560)
Coordinates:
* N_PROF (N_PROF) int64 0 1 2 3 4 5 6 ... 7554 7555 7556 7557 7558 7559
* DEPTH (DEPTH) float32 0.0 -5.0 -10.0 -15.0 ... -1395.0 -1400.0 -1405.0
Data variables:
LATITUDE (N_PROF) float32 ...
LONGITUDE (N_PROF) float32 ...
TIME (N_PROF) datetime64[ns] ...
DBINDEX (N_PROF) float64 ...
TEMP (N_PROF, DEPTH) float32 27.422163 27.422163 ... 4.391791
PSAL (N_PROF, DEPTH) float32 36.35267 36.35267 ... 34.910286
SIG0 (N_PROF, DEPTH) float32 ...
BRV2 (N_PROF, DEPTH) float32 ...
PCM_LABELS (N_PROF) int64 7 7 7 7 7 7 7 7 7 7 7 7 ... 2 2 2 2 2 2 2 2 2 2 2
Attributes:
Sample test prepared by: G. Maze
Institution: Ifremer/LOPS
Data source DOI: 10.17882/42182Prediction labels are automatically added to the dataset as PCM_LABELS because the option inplace was set to True. We didn’t specify the dim option because our dataset is CF compliant.
pyXpcm use a GMM classifier by default, which is a fuzzy classifier. So we can also predict the probability of each classes for all profiles, the so-called posteriors:
[10]:
m.predict_proba(ds, features=features_in_ds, inplace=True)
ds
[10]:
<xarray.Dataset>
Dimensions: (DEPTH: 282, N_PROF: 7560, pcm_class: 8)
Coordinates:
* N_PROF (N_PROF) int64 0 1 2 3 4 5 6 ... 7554 7555 7556 7557 7558 7559
* DEPTH (DEPTH) float32 0.0 -5.0 -10.0 -15.0 ... -1395.0 -1400.0 -1405.0
Dimensions without coordinates: pcm_class
Data variables:
LATITUDE (N_PROF) float32 ...
LONGITUDE (N_PROF) float32 ...
TIME (N_PROF) datetime64[ns] ...
DBINDEX (N_PROF) float64 ...
TEMP (N_PROF, DEPTH) float32 27.422163 27.422163 ... 4.391791
PSAL (N_PROF, DEPTH) float32 36.35267 36.35267 ... 34.910286
SIG0 (N_PROF, DEPTH) float32 ...
BRV2 (N_PROF, DEPTH) float32 ...
PCM_LABELS (N_PROF) int64 7 7 7 7 7 7 7 7 7 7 7 7 ... 2 2 2 2 2 2 2 2 2 2 2
PCM_POST (pcm_class, N_PROF) float64 3.999e-41 2.313e-41 ... 0.0 0.0
Attributes:
Sample test prepared by: G. Maze
Institution: Ifremer/LOPS
Data source DOI: 10.17882/42182which are added to the dataset as the PCM_POST variables. The probability of classes for each profiles has a new dimension pcm_class by default that goes from 0 to K-1.
Note
You can delete variables added by pyXpcm to the xarray.DataSet with the pyxpcm.xarray.pyXpcmDataSetAccessor.drop_all() method:
ds.pyxpcm.drop_all()
Or you can split pyXpcm variables out of the original xarray.DataSet:
ds_pcm, ds = ds.pyxpcm.split()
It is important to note that once the PCM is fitted, you can predict labels for any dataset, as long as it has the PCM features.
For instance, let’s predict labels for a gridded dataset:
[12]:
ds_gridded = pyxpcm.tutorial.open_dataset('isas_snapshot').load()
ds_gridded
[12]:
<xarray.Dataset>
Dimensions: (depth: 152, latitude: 53, longitude: 61)
Coordinates:
* latitude (latitude) float32 30.023445 30.455408 ... 49.41288 49.737103
* longitude (longitude) float32 -70.0 -69.5 -69.0 ... -41.0 -40.5 -40.0
* depth (depth) float32 -1.0 -3.0 -5.0 ... -1960.0 -1980.0 -2000.0
Data variables:
TEMP (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
TEMP_ERR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
TEMP_PCTVAR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
PSAL (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
PSAL_ERR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
PSAL_PCTVAR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
SST (latitude, longitude) float32 dask.array<chunksize=(53, 61), meta=np.ndarray>[13]:
m.predict(ds_gridded, features={'temperature':'TEMP','salinity':'PSAL'}, dim='depth', inplace=True)
ds_gridded
[13]:
<xarray.Dataset>
Dimensions: (depth: 152, latitude: 53, longitude: 61)
Coordinates:
* latitude (latitude) float64 30.02 30.46 30.89 ... 49.09 49.41 49.74
* longitude (longitude) float64 -70.0 -69.5 -69.0 ... -41.0 -40.5 -40.0
* depth (depth) float32 -1.0 -3.0 -5.0 ... -1960.0 -1980.0 -2000.0
Data variables:
TEMP (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
TEMP_ERR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
TEMP_PCTVAR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
PSAL (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
PSAL_ERR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
PSAL_PCTVAR (depth, latitude, longitude) float32 dask.array<chunksize=(152, 53, 61), meta=np.ndarray>
SST (latitude, longitude) float32 dask.array<chunksize=(53, 61), meta=np.ndarray>
PCM_LABELS (latitude, longitude) float64 7.0 7.0 7.0 7.0 ... 4.0 4.0 4.0where you can see the adition of the PCM_LABELS variable.
Vertical structure of classes¶
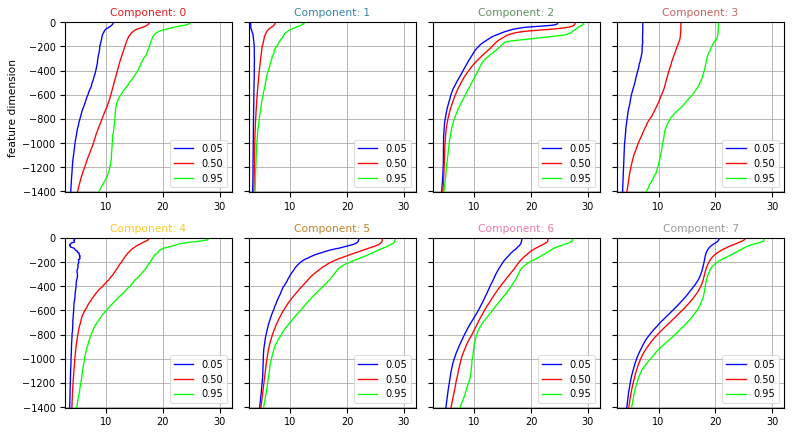
One key outcome of the PCM analysis if the vertical structure of each classes.
This can be computed using the :meth:pyxpcm.stat.quantile method.
Below we compute the 5, 50 and 95% quantiles for temperature and salinity of each classes:
[14]:
for vname in ['TEMP', 'PSAL']:
ds = ds.pyxpcm.quantile(m, q=[0.05, 0.5, 0.95], of=vname, outname=vname + '_Q', keep_attrs=True, inplace=True)
ds
[14]:
<xarray.Dataset>
Dimensions: (DEPTH: 282, N_PROF: 7560, pcm_class: 8, quantile: 3)
Coordinates:
* pcm_class (pcm_class) int64 0 1 2 3 4 5 6 7
* N_PROF (N_PROF) int64 0 1 2 3 4 5 6 ... 7554 7555 7556 7557 7558 7559
* DEPTH (DEPTH) float32 0.0 -5.0 -10.0 -15.0 ... -1395.0 -1400.0 -1405.0
* quantile (quantile) float64 0.05 0.5 0.95
Data variables:
LATITUDE (N_PROF) float32 27.122 27.818 27.452 26.976 ... 4.243 4.15 4.44
LONGITUDE (N_PROF) float32 -74.86 -75.6 -74.949 ... -1.263 -0.821 -0.002
TIME (N_PROF) datetime64[ns] 2008-06-23T13:07:30 ... 2013-03-09T14:52:58.124999936
DBINDEX (N_PROF) float64 1.484e+04 1.622e+04 ... 8.557e+03 1.063e+04
TEMP (N_PROF, DEPTH) float32 27.422163 27.422163 ... 4.391791
PSAL (N_PROF, DEPTH) float32 36.35267 36.35267 ... 34.910286
SIG0 (N_PROF, DEPTH) float32 23.601229 23.601229 ... 27.685583
BRV2 (N_PROF, DEPTH) float32 0.00029447526 ... 4.500769e-06
PCM_LABELS (N_PROF) int64 7 7 7 7 7 7 7 7 7 7 7 7 ... 2 2 2 2 2 2 2 2 2 2 2
PCM_POST (pcm_class, N_PROF) float64 3.999e-41 2.313e-41 ... 0.0 0.0
TEMP_Q (pcm_class, quantile, DEPTH) float64 11.22 11.22 ... 5.266 5.241
PSAL_Q (pcm_class, quantile, DEPTH) float64 35.13 35.13 ... 35.12 35.12
Attributes:
Sample test prepared by: G. Maze
Institution: Ifremer/LOPS
Data source DOI: 10.17882/42182Quantiles can be plotted using the :func:pyxpcm.plot.quantile method.
[15]:
fig, ax = m.plot.quantile(ds['TEMP_Q'], maxcols=4, figsize=(10, 8), sharey=True)
Geographic distribution of classes¶
Warning
To follow this section you’ll need to have Cartopy installed and working.
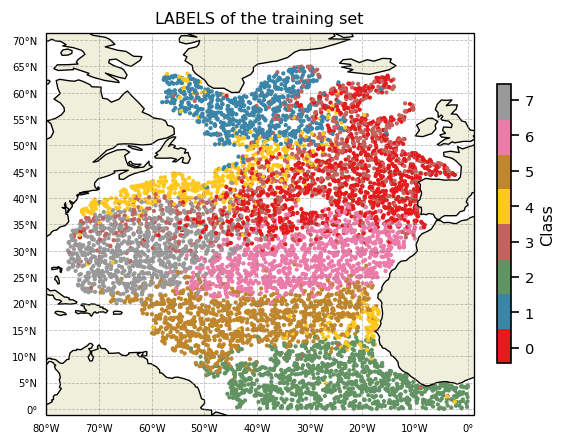
A map of labels can now easily be plotted:
[16]:
proj = ccrs.PlateCarree()
subplot_kw={'projection': proj, 'extent': np.array([-80,1,-1,66]) + np.array([-0.1,+0.1,-0.1,+0.1])}
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(5,5), dpi=120, facecolor='w', edgecolor='k', subplot_kw=subplot_kw)
kmap = m.plot.cmap()
sc = ax.scatter(ds['LONGITUDE'], ds['LATITUDE'], s=3, c=ds['PCM_LABELS'], cmap=kmap, transform=proj, vmin=0, vmax=m.K)
cl = m.plot.colorbar(ax=ax)
gl = m.plot.latlongrid(ax, dx=10)
ax.add_feature(cfeature.LAND)
ax.add_feature(cfeature.COASTLINE)
ax.set_title('LABELS of the training set')
plt.show()
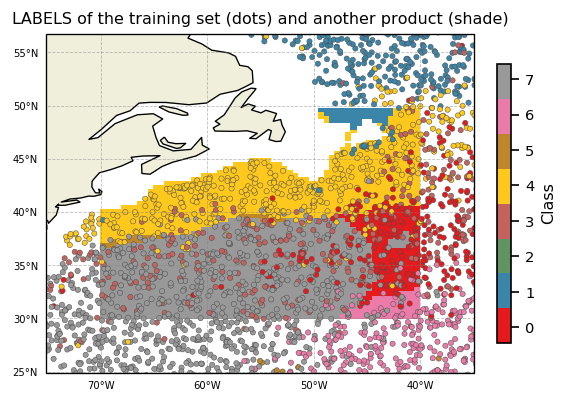
Since we predicted labels for 2 datasets, we can superimpose them
[17]:
proj = ccrs.PlateCarree()
subplot_kw={'projection': proj, 'extent': np.array([-75,-35,25,55]) + np.array([-0.1,+0.1,-0.1,+0.1])}
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(5,5), dpi=120, facecolor='w', edgecolor='k', subplot_kw=subplot_kw)
kmap = m.plot.cmap()
sc = ax.pcolor(ds_gridded['longitude'], ds_gridded['latitude'], ds_gridded['PCM_LABELS'], cmap=kmap, transform=proj, vmin=0, vmax=m.K)
sc = ax.scatter(ds['LONGITUDE'], ds['LATITUDE'], s=10, c=ds['PCM_LABELS'], cmap=kmap, transform=proj, vmin=0, vmax=m.K, edgecolors=[0.3]*3, linewidths=0.3)
cl = m.plot.colorbar(ax=ax)
gl = m.plot.latlongrid(ax, dx=10)
ax.add_feature(cfeature.LAND)
ax.add_feature(cfeature.COASTLINE)
ax.set_title('LABELS of the training set (dots) and another product (shade)')
plt.show()
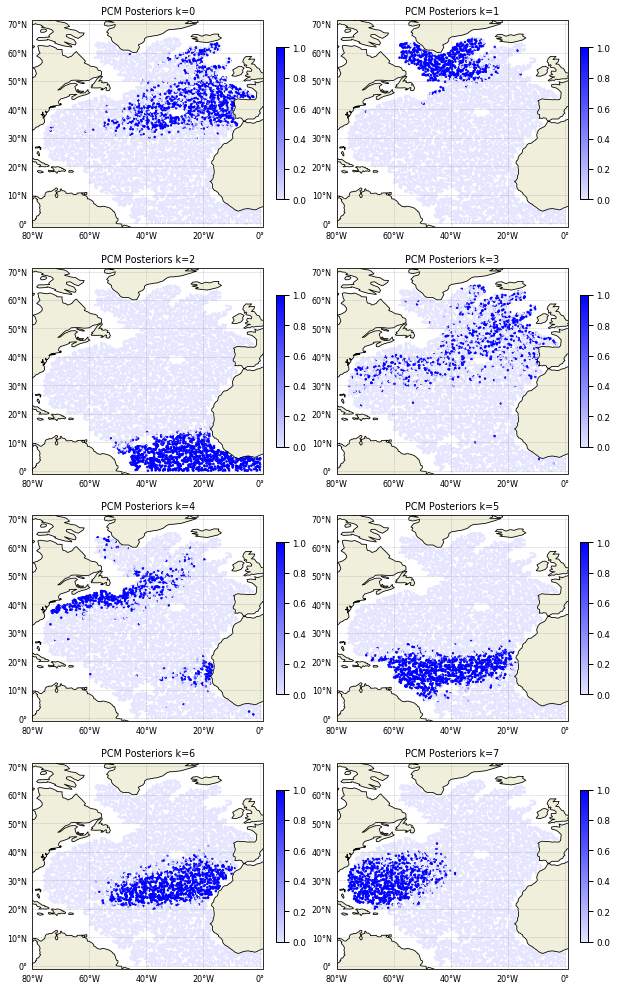
Posteriors are defined for each data point and give the probability of that point to belong to any of the classes. It can be plotted this way:
[18]:
cmap = sns.light_palette("blue", as_cmap=True)
proj = ccrs.PlateCarree()
subplot_kw={'projection': proj, 'extent': np.array([-80,1,-1,66]) + np.array([-0.1,+0.1,-0.1,+0.1])}
fig, ax = m.plot.subplots(figsize=(10,22), maxcols=2, subplot_kw=subplot_kw)
for k in m:
sc = ax[k].scatter(ds['LONGITUDE'], ds['LATITUDE'], s=3, c=ds['PCM_POST'].sel(pcm_class=k),
cmap=cmap, transform=proj, vmin=0, vmax=1)
cl = plt.colorbar(sc, ax=ax[k], fraction=0.03)
gl = m.plot.latlongrid(ax[k], fontsize=8, dx=20, dy=10)
ax[k].add_feature(cfeature.LAND)
ax[k].add_feature(cfeature.COASTLINE)
ax[k].set_title('PCM Posteriors k=%i' % k)